Blog »
Contract Analysis leveraging AI – A Technical Overview

Contract Lifecycle management is an area we have seen huge demand in over the last year or two. Many of our customers leverage our contract management solution for both authoring or contract repository. Over the last year, Ivalua’s AI team has been hard at work building an AI layer across the platform. One of the initial use cases the team is tackling is for contract analysis.
One significant area of Artificial Intelligence is language understanding, also called machine reading comprehension (MRC), and the new technologies in this field lead the way for thousands of new applications, such as sourcing, trend analysis, conversational agents, sentiment analysis, document management, cross-language business development, etc.
The data in this case is text from natural language, which is rarely structured data. It can be found in any human communications, either live conversations (chatbots, email, speech to text devices …) or stored publicly on the Internet or privately as textual data in databases. The comprehension of textual data requires the analysis of semantic and syntactic information in a block of text.
A specific application for Procurement involves contract analysis. At Ivalua, the AI team has conducted research to enable our platform to understand such text in the context of contracts or legal data. The goal being to manage risk by easily identifying obligations within contracts and ensuring that appropriate risk mitigating language is present within legal documents. The task of manually doing this or even using some basic automation would require weeks or months of human work to check each contract to ensure the right language is included given the context of the contract, the supplier and the buyer. Machine reading comprehension technologies enable us to do this automatically and much faster.
In order to mitigate their legal risk, some customers have put in place templates and standard clauses in a repository allowed by our product in order to standardize the contracts. Nevertheless, the final contracts include some text that may have been modified from the templates for convenience or during negotiations: removal of clauses, specific conditions, third parties inputs, stakeholder’s data different from the database, as well as modifications losing the tracking tags, such as different computer formats (Microsoft Office docs, Powerpoints, PDF, OpenOffice, …) and a printed format (scanned) for the final version.
Applying AI to understanding legal data typically faces two issues:
- The first is a limited amount of data to train AI algorithms, which usually require millions of data points, as opposed to humans, who are data-efficient, i.e., able to learn from a few examples. Not much contract data is available publicly, due to confidentiality.
- The second is that transfer or generalization is not guaranteed to other domains than the one on which an AI algorithm was trained. Legal language is quite different from common language, with words having specific meanings in contracts.
As in Invoice Data Capture (IDC), these limitations are overcome by learning, with little or no supervision, real world models from which meaningful features can be extracted for other tasks. In this case, language understanding is commonly performed on Language Models (LM), such as BERT by Google, or Machine Neural Translation (MNT) as MUSE by Facebook. The output of this process is a vectorial representation, called embedding, for each token or subtoken in a text, that encodes its meaning for further use in task-specific neural models. In particular, synonyms will be represented by close vectors. In the case of MUSE, these representations are invariant of the language, or cross-lingual, i.e., a word in French and its translation in English will have the same vector, which enables us to build language independent applications.
Encoding the meaning is a requirement for document analysis, making it independent of the wording. So, we encoded the content of each clause (without the title) from the clause repository by averaging the embeddings of the words it contains or using the maximum.
Nonetheless, it requires a few checkpoints: Did we choose the right method to reduce sequences of word embeddings into fixed size embeddings to represent blocks of texts? Are the contract segmentation and clause retrieval algorithms based on embeddings resistant to the text modifications we explained before? How do we measure the performance of the algorithms since no labelled data is available ?
The first immediate application of language understanding is clause repository management. Looking for clauses with similar embeddings to a clause of our choosing.
Obligations of the Parties 10
-> Obligations of the Parties 10
-> OBLIGATIONS OF THE PARTIES 1426
-> OBLIGATIONS OF THE PARTIES 1177
-> Obligations of the customer 1473
-> Obligation of verification, information and advice 160
One could observe that all the initially retrieved clauses shared the same title with the request clause. In practice, it is also possible to display clauses in 2D for the same qualitative analysis, using one color for each title :
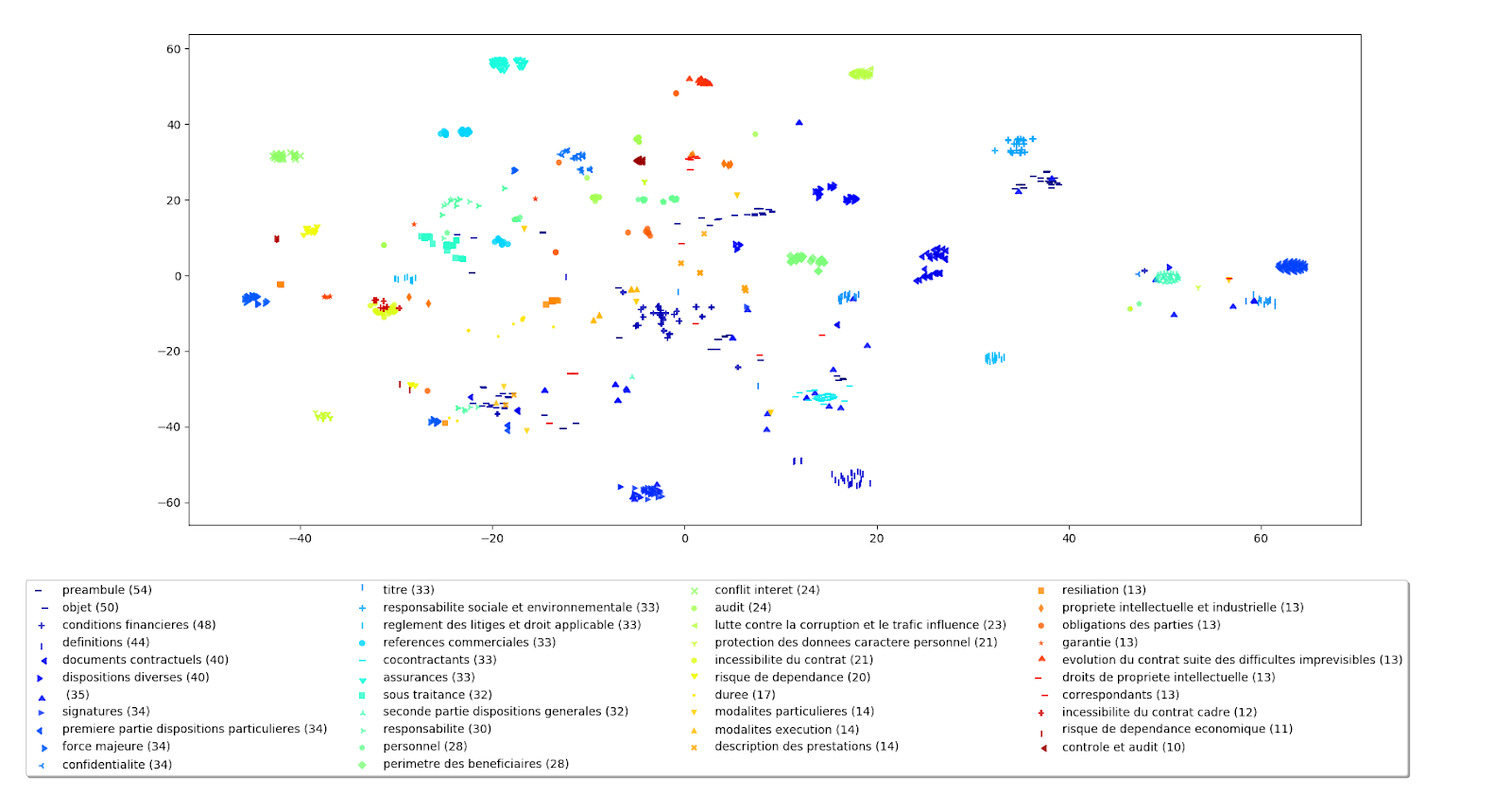
To avoid having hundreds of colors, we dropped clauses where the title appear less than 10 times in the dataset, and grouped clauses containing “annex” and “preamble” into 2 specific colors. This provided the necessary focus on relevant information.
We found that this kind of contract analysis enables not only the organization of clauses into categories by their legal meaning, but also to find lone or non-standard clauses and retitle or edit them.
Another feature that can be developed from these representations is automatic categorization by clustering clauses of similar meaning.
Similar clauses appear close in the visualization, for example, those with pricing/licencing information would be grouped. Such visual representations of legal clauses enable us to navigate into the space of clauses by their meaning and help the user quickly analyze and evaluate the quality of the clause repository (duplicates, mislabeled, modifications of original clauses…).
The second immediate application concerns the contracts themselves:
- contract segmentation into clauses
- retrieval of the original clause or template
- modifications performed from the original clauses – e.g., edits between the original clause and the final contract
- risk supervision: missing clauses, modified clauses, inaccurate data
Given the corpus of contracts (unlabeled) and the repository of clauses typically found in an organization, a similarity grouping based on the edit distance (ie the percentage of similar words) allows us to quickly and easily understand the relevance of existing clauses and inform areas of improvement or gaps.
When training data is available, further applications to build on top of these embeddings include entity recognition (dates, names, addresses, …), language detection, field retrieval (dates, petitioners, …) or question answering to answer any legal question.
We hope this article makes it clear to those interested, about the use case of AI technologies for contract analysis and the application of language understating capabilities. This is just an example of the work we’re doing at Ivalua, to learn more please contact us.
You May Also Like
-
Leveraging Generative AI to Transform Procurement in the Middle East
-
Best Practices for Securing Your Investment in Your External Workforce
-

Procurement Orchestration: Process, Strategies, Benefits